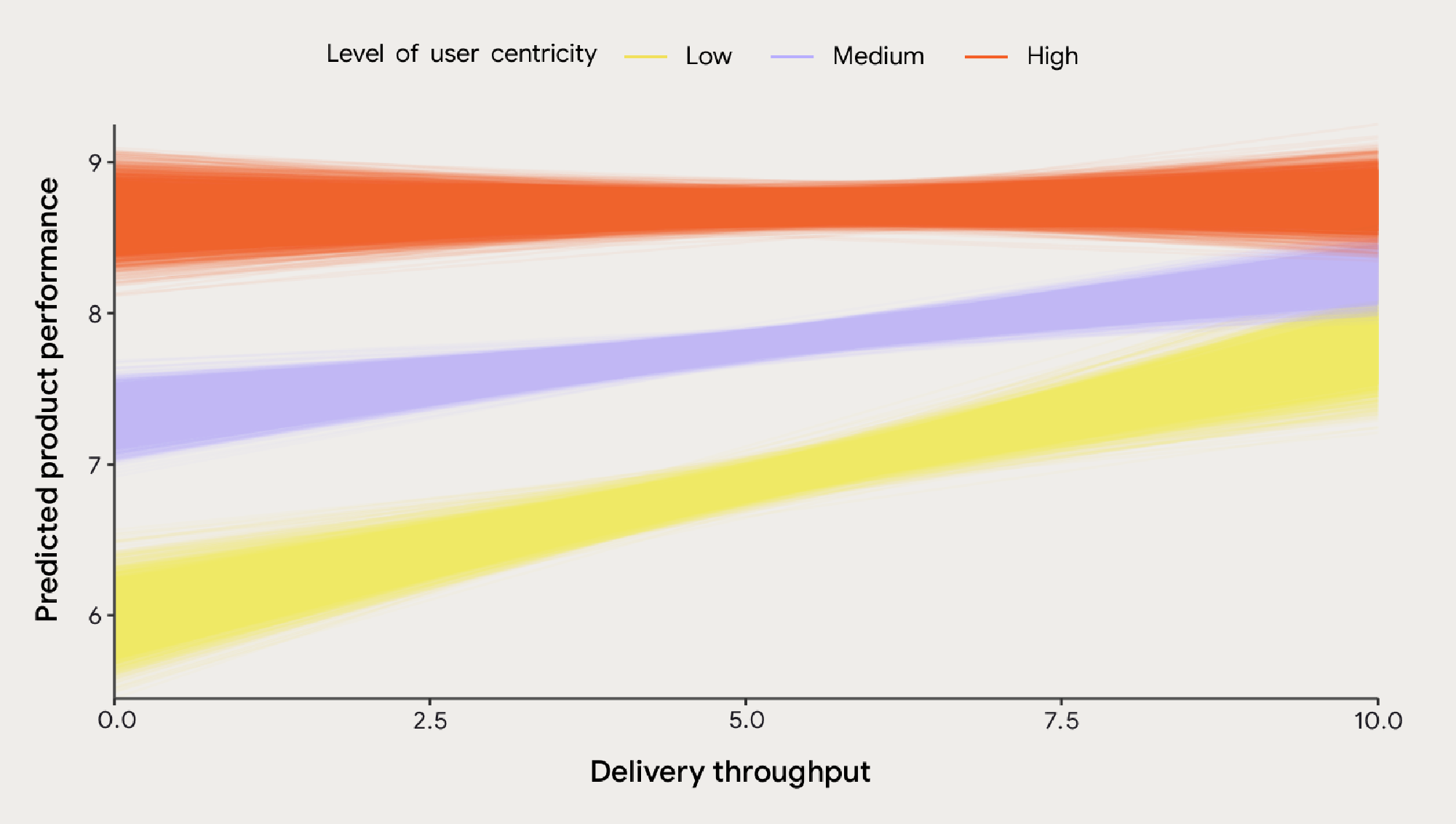
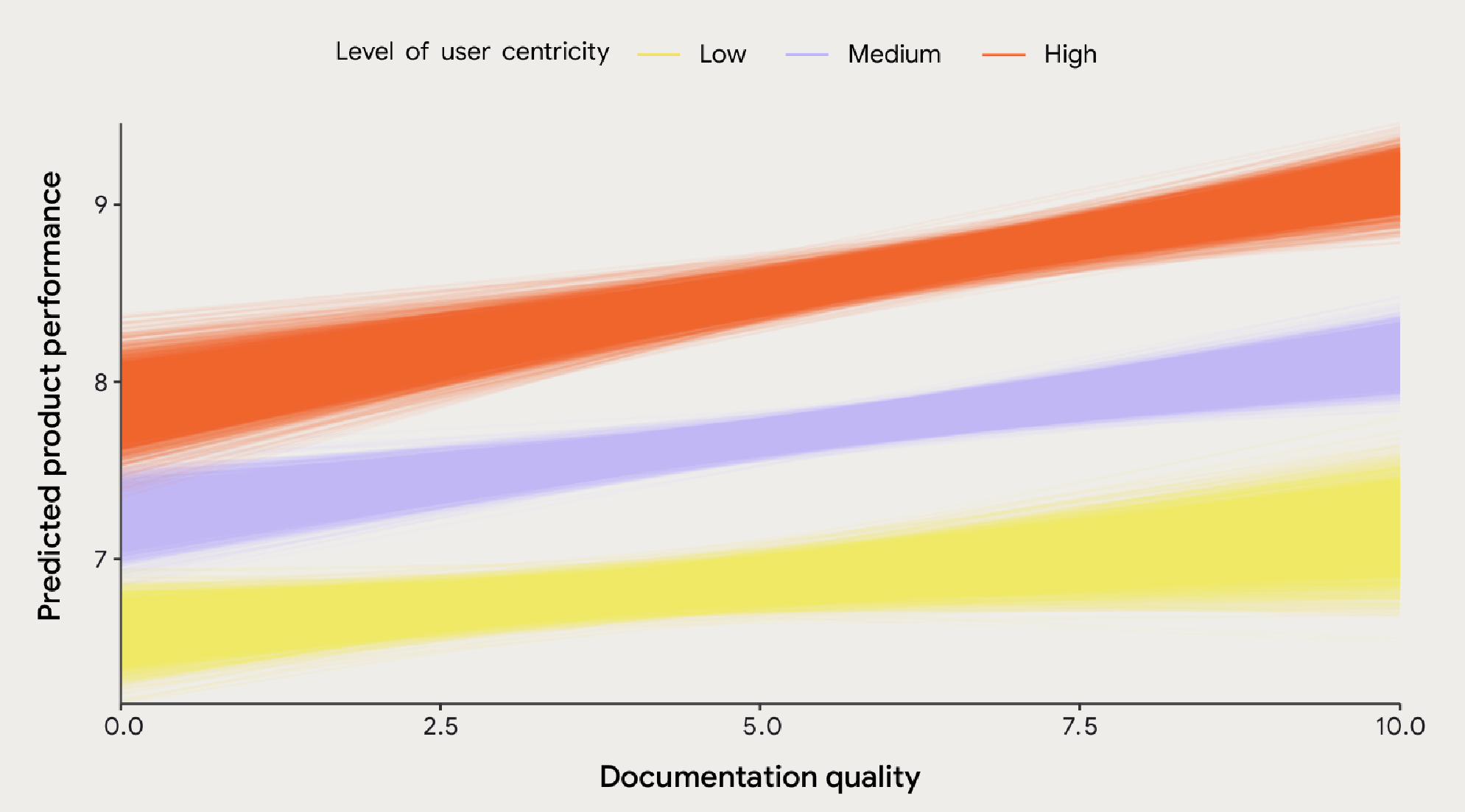
DORA에서 이번에 나온 보고서인 2025 State of AI-assisted Software Development를 확인하면서 VSM(Value Stream Management), 즉 가치 흐름 관리라는 개념을 처음 알게되었는데요. DevOps 관점에서 중요한 내용인 것 같아 한번 알아보기위해 내용을 준비했습니다.
소프트웨어 개발에서 VSM(Value Stream Management), 즉 가치 흐름 관리는 고객에게 가치를 전달하는 데 필요한 모든 단계를 시각화, 측정, 분석하고 지속적으로 개선하는 경영 방식입니다. 이는 원래 린(Lean) 제조 방식(도요타 생산 시스템)에서 유래했지만, 오늘날에는 복잡한 소프트웨어 개발 및 DevOps 수명 주기에 맞춰 핵심적인 전략으로 자리 잡았습니다. 핵심 목표는 '아이디어'가 '고객의 손에 닿아 가치를 창출'하기까지의 전체 과정을 더 빠르고, 효율적이며, 예측 가능하게 만드는 것입니다.
🌊 소프트웨어 개발에서의 '가치 흐름'
VSM을 이해하려면 먼저 '가치 흐름(Value Stream)'이 무엇인지 알아야 합니다.
소프트웨어 개발에서 가치 흐름은 단순히 '코딩'만을 의미하지 않습니다. 이는 아이디어가 처음 제안된 순간부터 고객이 그 기능을 사용하기까지의 모든 과정을 포함합니다.
- 시작: 비즈니스 아이디어 구상, 고객 요구사항 정의, 사용자 스토리 작성
- 기획/설계: 기획, UX/UI 디자인, 아키텍처 설계
- 개발: 코딩, 단위 테스트, 코드 리뷰
- 테스트/검증: QA 테스트, 통합 테스트, 보안 검증
- 배포/운영: 빌드, 배포(릴리스), 인프라 설정, 모니터링
- 피드백: 고객 사용 후 피드백 수집 (이 피드백은 다시 '시작' 단계로 이어짐)
VSM은 이 모든 단계뿐만 아니라, 단계와 단계 사이의 '대기 시간'까지 중요하게 다룹니다. 예를 들어, 코드는 완성되었지만 코드 리뷰를 2일간 기다리는 시간, QA 테스트 환경 배포를 반나절 기다리는 시간 등이 모두 흐름을 방해하는 '낭비'로 간주됩니다.
🎯 VSM의 핵심 목표: '낭비(Waste)' 제거
VSM의 근본적인 목적은 린(Lean) 사상과 마찬가지로 낭비를 식별하고 제거하여 흐름을 최적화하는 것입니다.
소프트웨어 개발에서의 낭비는 다음과 같습니다.
- 지연 (Delay): 승인 대기, 리뷰 대기, 테스트 환경 대기 등 작업이 멈춰있는 시간. (가장 큰 낭비)
- 핸드오프 (Handoff): 작업이 한 팀에서 다른 팀(예: 개발팀 -> QA팀)으로 넘어갈 때 발생하는 비효율.
- 결함 (Defects): 버그 수정, 재작업 등 이미 한 일을 다시 하는 것.
- 불필요한 프로세스 (Excess Processing): 과도한 문서 작업, 복잡하고 불필요한 승인 절차.
- 과잉 생산 (Overproduction): 당장 고객에게 필요하지 않거나 우선순위가 낮은 기능을 미리 만드는 것.
- 컨텍스트 스위칭 (Context Switching): 개발자가 여러 작업을 동시에 진행하며 발생하는 집중력 저하.
🛠️ VSM은 어떻게 작동하나요? (주요 활동)
VSM은 일회성 이벤트가 아니라 지속적인 개선 사이클입니다.
1. 가치 흐름 매핑 (Value Stream Mapping)
가장 첫 번째 단계는 현재 상태(As-Is)를 시각화하는 것입니다.
- 아이디어부터 배포까지 모든 단계를 그립니다.
- 각 단계의 담당 팀(예: 제품팀, 개발팀, QA팀, 운영팀)을 표시합니다.
- 각 단계에서 실제 작업이 일어나는 시간(Value-Added Time)과 대기하는 시간(Non-Value-Added Time)을 측정합니다.
2. 측정 (Measurement)
매핑된 흐름을 객관적인 데이터로 측정합니다. VSM은 "빠르게 일하는 것"이 아니라 "가치가 빠르게 흐르는 것"을 측정합니다.
주요 VSM 측정 지표 (Flow Metrics)
- 리드 타임 (Lead Time): (가장 중요) 아이디어가 요청된 시점부터 고객에게 전달(배포)될 때까지 걸린 총 시간.
- 사이클 타임 (Cycle Time): 실제 개발 작업이 시작된 시점부터 완료(배포)될 때까지 걸린 시간.
- 흐름 효율성 (Flow Efficiency): (실제 작업 시간 / 총 리드 타임) * 100%. 이 수치가 낮을수록(보통 15% 미만) 대기 시간이 대부분이라는 뜻입니다.
- 처리량 (Throughput): 특정 기간(예: 1주) 동안 완료되어 배포된 작업(기능, 스토리)의 수.
- 작업 진행률 (WIP - Work in Progress): 현재 동시에 진행 중인 작업의 수. WIP가 너무 많으면 병목 현상이 발생하고 리드 타임이 길어집니다.
3. 분석 (Analyze)
측정된 데이터를 기반으로 **병목 구간(Bottleneck)**을 식별합니다.
- "어디서 대기 시간이 가장 많이 발생하는가?" (예: 코드 리뷰, QA 테스트)
- "어느 단계에서 결함(재작업)이 가장 많이 발생하는가?"
- "팀 간의 핸드오프가 너무 잦거나 비효율적이지 않은가?"
4. 개선 (Improve)
데이터로 식별된 가장 큰 병목 지점부터 개선(카이젠, Kaizen)을 실행합니다.
- 예시:
- 병목이 'QA 테스트'라면 -> 테스트 자동화 비율을 높입니다.
- 병목이 '코드 리뷰 대기'라면 -> 리뷰 정책을 변경하거나 리뷰 시간을 확보합니다.
- 병목이 '배포'라면 -> CI/CD 파이프라인을 고도화합니다.
- 개선 후, 다시 1번(매핑)으로 돌아가 효과를 측정하고 새로운 병목을 찾아 개선을 반복합니다.
🤝 VSM, 애자일(Agile), 그리고 데브옵스(DevOps)
VSM은 애자일이나 데브옵스와 경쟁하는 개념이 아니라, 이들을 통합하고 비즈니스 가치에 연결하는 상위 개념입니다.
- 애자일 (Agile): 주로 개발 팀 내부의 유연하고 반복적인 작업 방식(스프린트, 스크럼)에 중점을 둡니다. "어떻게 효율적으로 개발할 것인가?"
- 데브옵스 (DevOps): 개발(Dev)과 운영(Ops) 간의 장벽을 허물어 배포 속도(CI/CD)와 안정성을 높이는 문화 및 기술 방식입니다. "어떻게 빠르고 안정적으로 배포할 것인가?"
- VSM (Value Stream Management): 이 모든 활동(애자일, 데브옵스 포함)을 비즈니스 관점에서 End-to-End(시작부터 끝까지)로 연결합니다. "우리의 애자일과 데브옵스 활동이 정말로 고객에게 가치를 더 빨리 전달하고 있는가?"를 측정하고 관리합니다.
✨ VSM 도입의 핵심 이점
- 전체 프로세스 가시성 확보: '블랙박스'처럼 느껴졌던 소프트웨어 개발 전체 과정을 모든 이해관계자가 투명하게 볼 수 있습니다.
- 데이터 기반 의사결정: '느낌'이 아닌 실제 데이터(리드 타임, 효율성)를 기반으로 어디를 개선해야 할지 정확히 알 수 있습니다.
- 병목 현상 해결 및 속도 향상: 낭비와 대기 시간을 줄여 고객에게 가치를 전달하는 속도(Time-to-Market)를 획기적으로 단축시킵니다.
- 팀 간 사일로(Silo) 제거: 제품, 개발, QA, 운영팀이 각자의 목표가 아닌 '가치 전달'이라는 공동의 목표를 향해 협업하게 만듭니다.
- 비즈니스 성과 연계: 개발팀의 활동(배포 속도, 처리량)이 실제 비즈니스 성과(매출, 고객 만족)에 어떻게 기여하는지 명확히 연결할 수 있습니다.
소프트웨어 개발에서 가치 흐름 관리(VSM)를 통해 아이디어 구상부터 고객에게 가치를 전달하기까지의 모든 단계를 시각화하고, '흐름 지표'(Flow Metrics)를 통해 객관적으로 측정 및 분석할 수 있습니다.
VSM의 핵심은 '가치 흐름 매핑'으로 현재 상태를 파악하고, '낭비'(특히 대기 시간)와 병목 구간을 식별하여 지속적으로 개선하는 것입니다. 이는 애자일(Agile), 데브옵스(DevOps)와 같은 활동들이 실제로 비즈니스 가치에 어떻게 기여하는지 명확히 연결하고, 데이터 기반 의사결정을 통해 전체적인 가치 전달 속도를 높이는 핵심 경영 방식입니다.
지금까지 소프트웨어 개발에서의 가치 흐름 관리(VSM)에 대해 알아보는 시간을 가졌습니다...! 끝...!
유익하게 보셨다면 공감을 눌러주고, 댓글로 의견을 공유해 남겨주시면 감사하겠습니다!
'DevOps' 카테고리의 다른 글
| [DevOps] 2024 State of DevOps Report Part 3 (사용자 중심 접근) (1) | 2025.03.21 |
|---|---|
| [DevOps] 2024 State of DevOps Report Part 2 (플랫폼엔지니어링) (1) | 2025.03.17 |
| [DevOps] 2024 State of DevOps Report Part 1 (AI) (0) | 2025.03.07 |
| [DevOps] AWS vs Azure vs GCP vs NCP 사용, 인기도, 관심도 비교 (0) | 2024.02.13 |
| [DevOps] 여러가지 CI/CD 툴 사용, 인기도, 관심도 비교 (1) | 2024.02.02 |